Transient Execution Side Channels
The basic idea of UPEC is to check if a set of confidential information, in short the secret, can have a subtle effect on the way a program executes. This is formalized in the notion of unique program execution. A program executes uniquely w.r.t. a secret if and only if the sequence of valuations to the set of program visible state variables is independent of the value of the secret, in every clock cycle of program execution. In other words, UPEC checks for variations of behavior that are visible in the microarchitecture (also called “microarchitectural footprint”) but not at the ISA level.
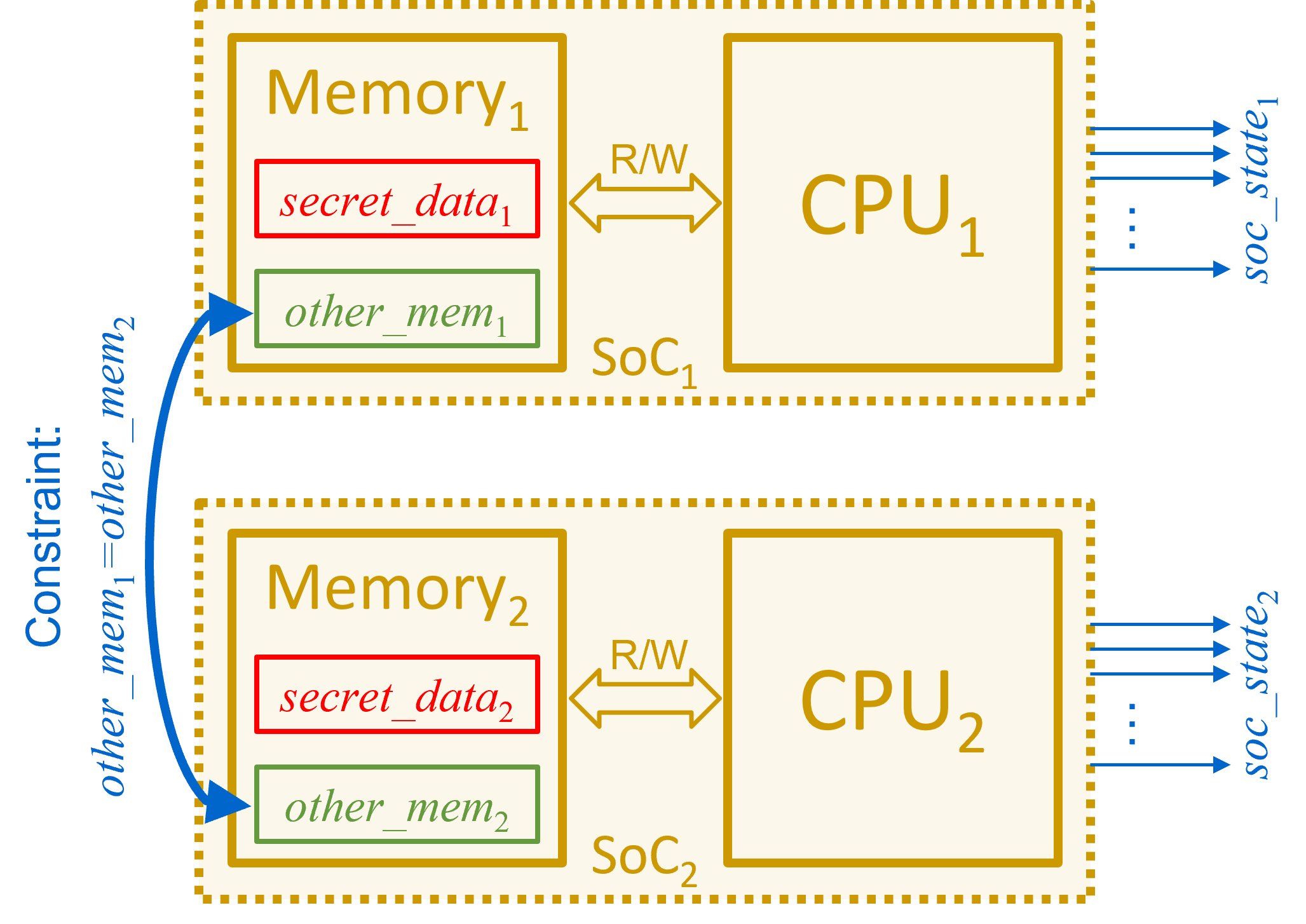
UPEC verifies this requirement by checking a 2-safety property (= a property that relates to 2 execution traces rather than one) on a tailor-made miter model (Fig. 1). In this model, the two CPU instances execute the same program, since the two memories must have the same content. This content is not specified so that the CPUs can execute any program. The only difference between the two instances can be in the protected memory location hosting the secret. Based on this model, assuming both CPUs start from the same initial state, we check if the secret data lead to different executions in the two instances for any program.
To reason about the UPEC proof for an OOO processor, we need to define an abstract model for such processors. This model will be used to prune the state space explored in UPEC by removing unreachable sub-spaces violating rules of out-of-order execution.
The abstract OOO-processor model consists of 1) different functional units (FU) and sets of buffers for in-flight instructions (pipeline bookkeeping buffers), 2) a reorder buffer (ROB) which ensures that the instructions commit in program order, and 3) a prediction unit (PU) which resolves the outstanding speculations in the pipeline by determining correct and incorrect predictions.
Every instruction in the pipeline (in the ROB or pipeline bookkeeping buffers) has two identifiers:
- ID of the assigned ROB Slot (ROB ID): A unique identifier that reflects the program order.
- Speculation tag: An identifier that reflects the level of speculation, i.e., the number of unresolved branches before the instruction. It should be noted that to support nested speculation, there must be an ordering between the speculation tags, so that misprediction on an earlier branch discard also all the subsequent branches. Encoding of the order of the tags is implementation-specific.
Branches and other instructions which can initiate speculation (SPI instructions), have another identifier, called spawn tag. The spawn tag of an SPI instruction determines the speculation tag of the instructions that are dispatched after the considered SPI instruction. The prediction unit uses the spawn tag of the executed branch instruction to resolve the outstanding speculative instructions.
Check out our Verification IP on GitHubSecure-by-Construction Design Methodology
In our paper Secure-by-Construction Design Methodology for CPUs: Implementing Secure Speculation on the RTL, we present a novel secure-by-construction RTL design methodology based on a generic information flow tracking infrastructure. The methodology uses formal verification to systematically detect possible leakage paths and to customize the generic infrastructure accordingly for the design. We propose an iterative flow that semi-automatically leads to an RTL design that is guaranteed to be secure w.r.t. transient execution attacks. A case study for the methodology is conducted on BOOMv3, an open-source RISC-V processor with a deep out-of-order pipeline, and the resulting secure RTL design is benchmarked on an FPGA setup. Our design outperforms a design based on conservative countermeasures, improving the incurred overhead by 3x / 4x (depending on the threat model) while maintaining the same level of security.
To show the feasibility of our design methodology, we present proof-of-concept mitigation of all TES vulnerabilities according to the threat models previously. The repository linked below contains a case study of the proposed design flow, conducted on BOOMv3, in which we developed a secure RTL implementation. The secure design delivers an average performance overhead of 5.2 % and 36.0 % compared to the insecure baseline design, depending on the threat model. Our case study shows that RTL design details can create timing variations that are not visible in the more abstract models. Therefore, a systematic methodology based on cycle- and bit-accurate models is necessary.
The implemented design, to the best of our knowledge, is the first formally verified RTL hardware implementation of a processor featuring secure speculation with competitive performance. The design is capable of running a Linux operating system and is comparable to medium-sized application processors used in the industry. The formal guarantees for our implementation are provided by Unique Program Execution Checking.
Timing Side Channels
[Detailed content goes here]
Functional Security Bugs in SoCs
[Detailed content goes here]
Operation Integrity in SoCs
[Detailed content goes here]